
SQL Practice With D&D Data
Below are some SQL challenges I made for myself as practice, using a database I built from public D&D Beyond character sheets.
I tried to do as much of the data manipulation in SQL as possible, though I ran the queries through pandas for ease of inspection/visualization.
import sqlite3
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
# Connect to the database
con = sqlite3.connect("../../db/main_11-30-21.db")
The first one is pretty simple. This one counts all feats selected by all characters. The only tricky thing is that you have to do a tiny bit of entity resolution, since some feats include optional features in the name: “Resilience (Constitution)” and “Resilience (Wisdom)” should normalize to “Resilience.” I accomplished this with a subquery.
query = '''
SELECT
feats_clean.featName,
COUNT (feats_clean.featName) as featCount
FROM (
SELECT
CASE
WHEN INSTR(fd.featName, ' -') != 0
THEN SUBSTR(fd.featName, 1, INSTR(fd.featName, ' -') - 1)
WHEN INSTR(fd.featName, ' (') != 0
THEN SUBSTR(fd.featName, 1, INSTR(fd.featName, ' (') - 1)
ELSE
fd.featName
END featName
FROM feats
LEFT JOIN featDefinition fd ON feats.featDefinitionId = fd.Id
WHERE
fd.isHomebrew = 0
) feats_clean
GROUP BY featName
ORDER BY featCount DESC
;
'''
Let’s display the top 10 most commonly picked feats. The only thing here that suprises me is that Grappler is #2. It’s widely considered bad, but apparently ~31,000 characters didn’t get the memo.
df = pd.read_sql_query(query, con)
df.iloc[0:10]
| featName | featCount | |
|---|---|---|
| 0 | War Caster | 32555 |
| 1 | Grappler | 31612 |
| 2 | Tough | 22710 |
| 3 | Sharpshooter | 16776 |
| 4 | Alert | 16656 |
| 5 | Lucky | 15860 |
| 6 | Observant | 15686 |
| 7 | Resilient | 15638 |
| 8 | Magic Initiate | 14927 |
| 9 | Sentinel | 14334 |
This next one calculates the total value in gold pieces of all of a character’s currencies and inventory items. It also pulls their tier of play, based on their character levels. The idea was to see how closely tier-wise wealth averages resemble the estimates provided in the Dungeon Masters’ Guide.
Total character level is not a stored value and had to be generated from class levels, which matters in the case of multiclass characters.
Total gold value is not a stored value and has to be calculated from the converted value of all currencies plus the total cost of all inventory items.
query = '''
SELECT
summed_levels.charId,
CASE
WHEN summed_levels.charLevel BETWEEN 1 AND 4 THEN 1
WHEN summed_levels.charLevel BETWEEN 5 AND 10 THEN 2
WHEN summed_levels.charLevel BETWEEN 11 AND 16 THEN 3
WHEN summed_levels.charLevel BETWEEN 17 AND 20 THEN 4
ELSE 5
END tier,
0.01*(c.cp) + 0.1*(c.sp) + 0.5*(c.ep) + c.gp + 10*(c.pp) AS gold,
i.total_cost AS inventory_value
FROM (
SELECT
charId,
SUM(classLevel) AS charLevel
FROM
classes
GROUP BY
charId
) summed_levels
LEFT JOIN
currencies c ON c.charId = summed_levels.charId
LEFT JOIN
(
SELECT
charId,
SUM(iDef.cost * quantity) AS total_cost
FROM
inventory
LEFT JOIN
itemDefinition iDef ON iDef.id = inventory.itemDefinitionId
GROUP BY
charId
) i ON i.charId = summed_levels.charId
;
'''
df = pd.read_sql_query(query, con)
df
| charId | tier | gold | inventory_value | |
|---|---|---|---|---|
| 0 | 2510 | 1 | 130.0 | 155.97 |
| 1 | 2778 | 1 | 0.0 | NaN |
| 2 | 2806 | 1 | 135.0 | 134.00 |
| 3 | 2903 | 3 | 0.0 | NaN |
| 4 | 2988 | 1 | 7.6 | 0.20 |
| ... | ... | ... | ... | ... |
| 987217 | 52414013 | 1 | 0.0 | 100.41 |
| 987218 | 52414055 | 2 | 27.0 | 57.50 |
| 987219 | 52414131 | 4 | 10.0 | 162.10 |
| 987220 | 52414159 | 4 | 0.0 | 30.20 |
| 987221 | 52414174 | 1 | 0.0 | 300.00 |
987222 rows × 4 columns
That one was useful as a coding exercise, but I realized after browsing the data that these numbers probably aren’t very meaningful. It seems like most people aren’t tracking wealth very closely on these sheets - lots of characters have no gold and total inventory value of 0. Many of these characters are theory-crafts that haven’t actually seen play, so they don’t have items or money.
And even if we exclude these characters, the median total wealth is much lower than I’d expect (though note that this doesn’t include magic items, which don’t have set prices in 5th edition).
df['inventory_value'] = df.inventory_value.fillna(0)
df['wealth'] = df.gold + df.inventory_value
df[(df.gold != 0) & (df.inventory_value != 0)].groupby('tier').wealth.describe()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| tier | ||||||||
| 1 | 308188.0 | 3.999601e+06 | 2.741318e+08 | 0.35 | 103.72 | 154.500 | 282.6000 | 2.493229e+10 |
| 2 | 207866.0 | 1.834248e+06 | 1.868466e+08 | 0.21 | 125.20 | 240.750 | 1081.3000 | 2.493229e+10 |
| 3 | 44546.0 | 8.459603e+06 | 4.193392e+08 | 1.63 | 123.50 | 340.005 | 1747.4575 | 2.493229e+10 |
| 4 | 34418.0 | 1.531096e+10 | 2.830436e+12 | 1.02 | 94.50 | 168.245 | 1141.8000 | 5.251050e+14 |
These numbers are… suspicious. Median wealth at tier 4 is only 168 gp? I inspected some of the tier 4 characters and it looks like they are either theory-crafts, without items, or character sheets that only list magic items (which have no price). Ah well - limitation of the data.
But the outliers are really something. Who is this character with over 6 billion gp in wealth?
df[df.wealth == df.wealth.max()]
| charId | tier | gold | inventory_value | wealth | |
|---|---|---|---|---|---|
| 974732 | 51974698 | 4 | 2.493229e+10 | 5.250801e+14 | 5.251050e+14 |
Alright, let’s end with something a little more interesting. This query gets the highest magic item rarity of each character. It requires multiple nested queries since, first of all, rarity has to be converted to a numeric value in order to get the “highest,” and because, as before, character level has to be inferred.
query = '''
SELECT
summed_levels.charId,
summed_levels.charLevel,
char_max_rarity.max_rarity
FROM (
SELECT
charId,
SUM(classLevel) AS charLevel
FROM
classes
GROUP BY
charId
) summed_levels
LEFT JOIN
(
SELECT
charId,
MAX(rarity) AS max_rarity
FROM
(SELECT
charId,
CASE
WHEN iDef.rarity = 'Uncommon' THEN 1
WHEN iDef.rarity = 'Rare' THEN 2
WHEN iDef.rarity = 'Very Rare' THEN 3
WHEN iDef.rarity = 'Legendary' THEN 4
WHEN iDef.rarity = 'Artifact' THEN 5
ELSE 0
END rarity
FROM
inventory
LEFT JOIN
itemDefinition iDef ON iDef.id = inventory.itemDefinitionId
) inv_numeric_rarity
GROUP BY
charId
) char_max_rarity ON char_max_rarity.charId = summed_levels.charId
WHERE
char_max_rarity.max_rarity > 0
AND
summed_levels.charLevel BETWEEN 1 AND 20
;
'''
df = pd.read_sql_query(query, con)
df
| charId | charLevel | max_rarity | |
|---|---|---|---|
| 0 | 4534 | 20 | 4 |
| 1 | 4565 | 20 | 5 |
| 2 | 4668 | 3 | 1 |
| 3 | 4952 | 3 | 1 |
| 4 | 5505 | 1 | 4 |
| ... | ... | ... | ... |
| 271635 | 52413585 | 20 | 3 |
| 271636 | 52413597 | 20 | 4 |
| 271637 | 52414003 | 9 | 1 |
| 271638 | 52414131 | 20 | 4 |
| 271639 | 52414159 | 18 | 2 |
271640 rows × 3 columns
Let’s make a box plot and see what the distribution by tier looks like.
import matplotlib.ticker as ticker
sns.set_style("darkgrid")
dims = (10.7, 7.27)
fig, ax = plt.subplots(figsize=dims)
ax = sns.boxplot(
x='max_rarity',
y='charLevel',
data=df,
ax=ax
)
ax.set_xticklabels([
'Uncommon',
'Rare',
'Very Rare',
'Legendary',
'Artifact'
], fontsize=12)
ax.set_ylabel('character level', fontsize=12)
ax.set_xlabel('')
ax.set_title('Highest Magic Item Rarity by Character Level', fontsize=14)
ax.yaxis.set_major_locator(ticker.MultipleLocator(2))
ax.yaxis.set_major_formatter(ticker.ScalarFormatter())
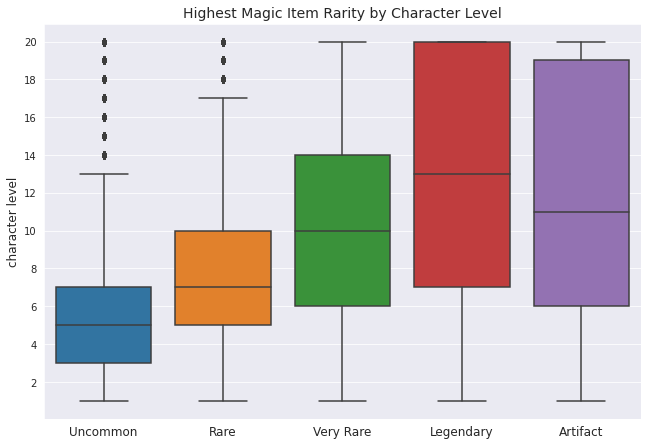
Now we’re talking. A couple interesting things to note:
- The spread of the distribution increases as you move up the rarity ladder. Most characters with only an uncommon item are between levels 3 and 7, but characters who have at least a legendary- or artifact-rarity item are all sorts of levels.
- Artifact rarity actually has a lower median character level than legendary. I’m assuming this is because DMs like to drop an artifact into play a little earlier for plot reasons: call it the “one ring” effect (this theory is supported by the fact that it disappears if I remove homebrew items)
If you enjoyed this, consider checking out my other posts. I plan to do more analysis with this data in the near future.