
ACH 2021: Computational Analysis of Book Reviews
The following is a lightly-edited transcription of my presentation with Dan Sinykin for ACH 2021, part of a roundtable on “Computational Analysis of Book Reviews”
For our presentation, I’m going to share some exploratory analysis from our current project, material that I hope will help get a conversation started about what book review data can teach us about the book market and literary culture. In particular, I’m going to suggest that a remarkable amount of insight can be gleaned from book reviews simply by coding information on whether or not a specific publication reviewed a book, without encoding anything on the content of a review.
We’re working with a dataset derived from the Book Review Index between the years 1965 and 2000, which was digitized by Richard So and my co-presenter Dan Sinykin. Somewhere in your university library, there is probably a copy of the Book Review Index, a series of large volumes that index the book reviews published by hundreds of periodicals, mostly American, ranging from academic journals, mainstream newspapers, literary magazines, and smaller magazines targeting a specialized audience.
A single entry in the Index might look like this. Each unique title has such an entry, listing publication, volume, edition, and page number for the review. On the surface, this doesn’t tell us much: nothing about what the review says, only whether it exists. But the decision to review a book is itself an act of valuation; it reflects editors’ suspicions that this book will be of interest to their readers. Can we learn something about the American literary marketplace between 1965 and 2000 from an aggregate picture of these acts of valuation?

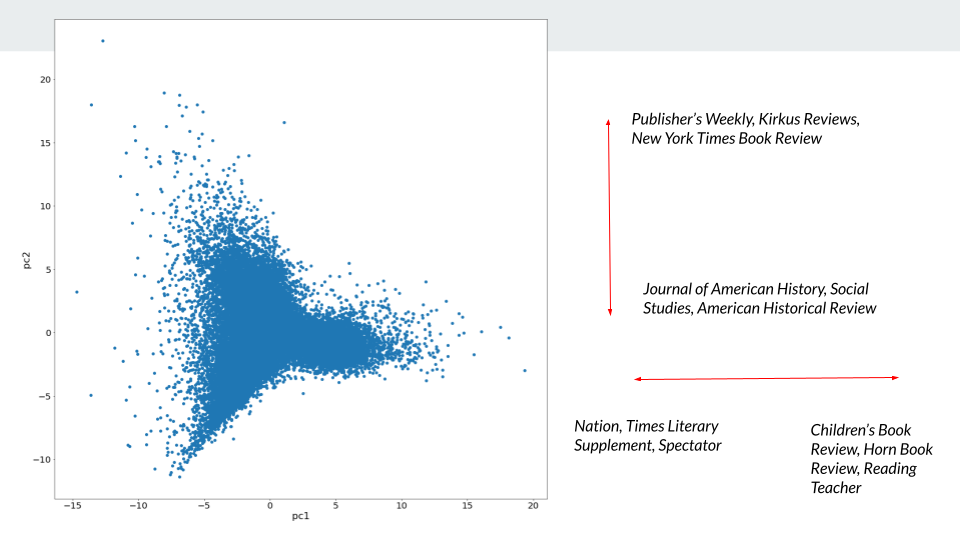
Preliminary results suggest: yes! I represented each book as a binary-encoded vector with 285 dimensions, one for each review outlet. The result is a title-review matrix with about 800k rows. Many of those titles were only reviewed a handful of times, so I’ve restricted the data to only those ~33,000 titles that were reviewed at least 10 times. Does this data have any natural clusters? Do books that tend to be reviewed by the same publications have any coherent thematic or social grouping?
Restricting ourselves to only the first two principal components gives the following plot. PCA is not a great way of working with binary data, but it’s really nice for visualization. We can inspect the components to get a sense of which dimensions are contributing most to each of our two axes. Principal component 1 might be called the children - adult axis: books are pulled right by reviews in Children’s Book Review and Reading Teacher, and pulled left by Nation and Spectator. PC2 might be loosely described as the academic - mainstream axis: titles are pulled up by Publisher’s Weekly, Kirkus Reviews, and the NYTBR, but pulled down by niche academic journals like American Historical Review and Social Studies.
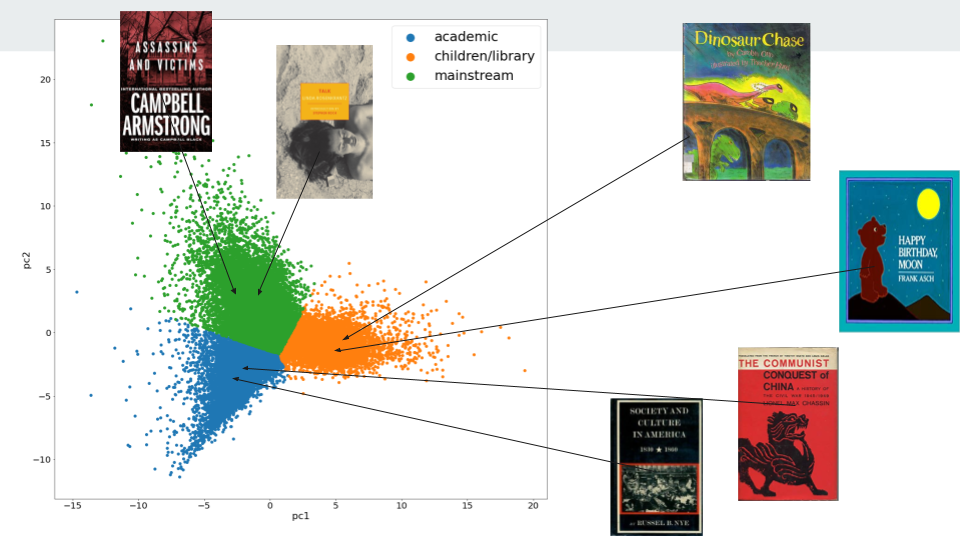
The whole plot has a 3-part structure, so I clustered the data with KMeans and came up with the following heuristic labels. Some of the most centrally-located books in the blue, academic cluster include Russel Nye’s Society and Culture in America, 1830-1860 and Lionel Chassin’s The Communist Conquest of China. The orange center, meanwhile, includes Frank Asch’s Happy Birthday Moon and Carolyn Otto’s Dinosaur Chase. And green, the most diffuse, includes many novels, such as Campbell Black’s horror novel Assassins and Victims and Linda Rosencrantz’s Talk.
This projection undersells the complexity of the data, since the first two principal components explain only about 5% of the variance. Another way of assessing the “review similarity” of two books is with a distance metric like cosine distance. Since many books with a small number of reviews have an identical review profile, I’m using this metric at the level of authors rather than books. So, for example, consider the five “closest” authors by review profile to novelist Toni Morrison.
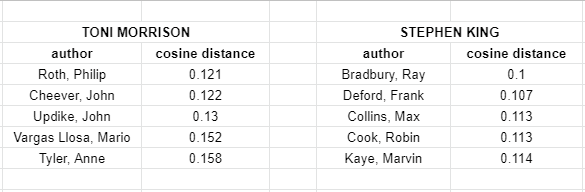
We see mostly other mainstream prizewinning American authors. As Dan pointed out to me, in terms of academic status, Anne Tyler is the most surprising one here: she lacks the academic canonization of these other authors but is reviewed in similar venues. Conversely, the five closest authors to Stephen King include spec-fic/fantasy novelists like Ray Bradbury and Marvin Kaye; Frank Deford, an author of sports novels; mystery novelist Max Collins; and Robin Cook, an author of medical thrillers. Remember, this is based on nothing more than the fact that these authors tend to be reviewed by similar publications. There is an intuitive sort of market- or status-based similarity here, even if these authors are working in very different textual genres. What’s incredible about this data is how it gives us a portrait of the enclosures and silos of the book review space. Morrison and King are both very influential authors, but are speaking to largely different audiences; there is no overlap between their “most similar” authors. I’ve chosen two high-profile authors for this illustration, but in principle this data would allow us to make similar comparisons between other authors and their respective audiences.